Workflow
Test Pandas Python online - Valutazione delle competenze pre-assunzione
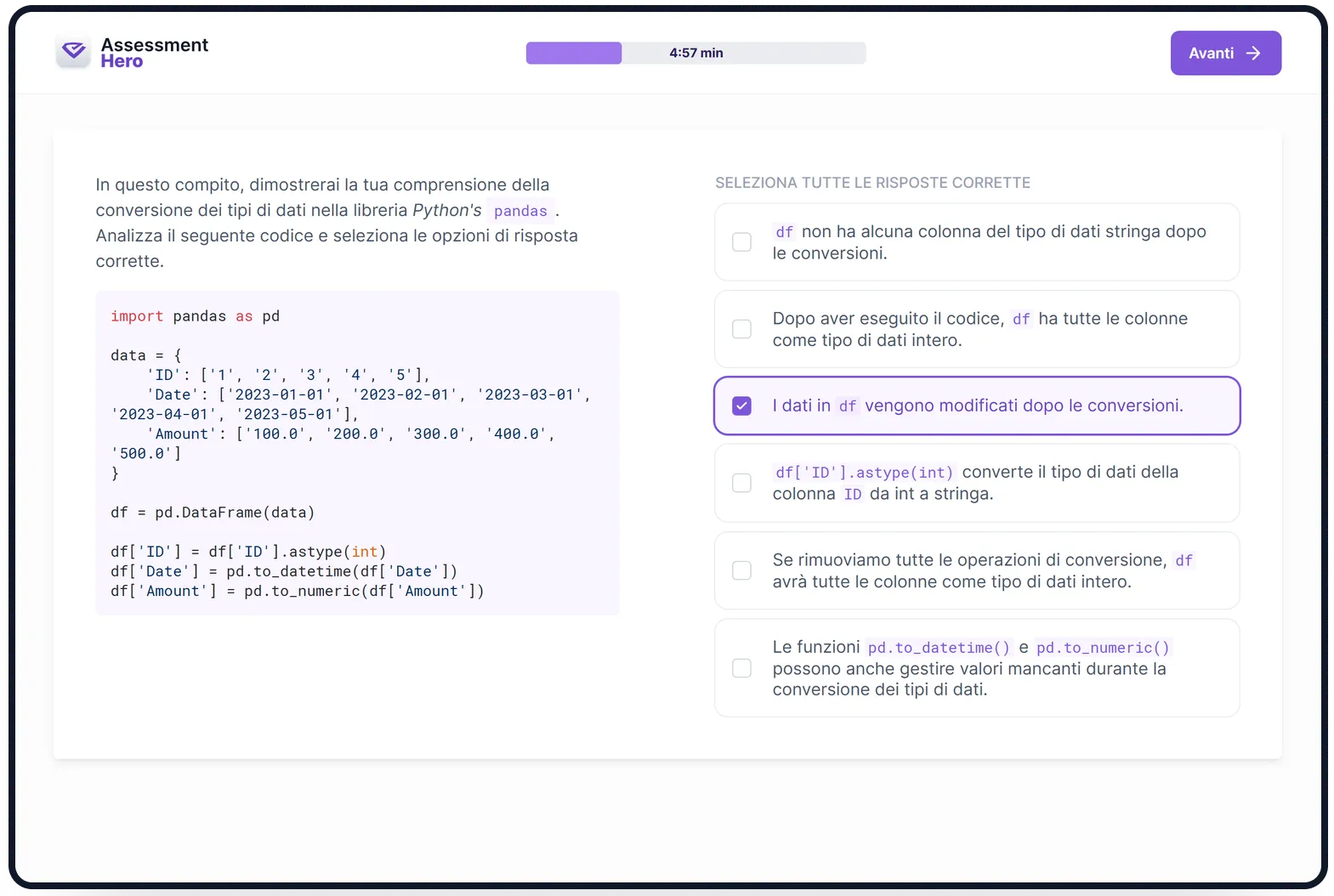

Di cosa tratta il test?
Questo test valuta la competenza dei candidati nell'utilizzare Pandas, una potente libreria Python per l'analisi e la manipolazione dei dati. Misura la loro capacità di pulire, trasformare e visualizzare set di dati complessi utilizzando questo framework.
Competenze coperte
Creatore della prova

Tim Funke
Ingegnere software presso Telekom
Con un'esperienza di otto anni presso Deutsche Telekom, Tim Funke ha dimostrato non solo la sua padronanza come ingegnere software, ma anche eccellenza come ingegnere DevOps e ingegnere dei dati. Gestisce tecnologie come Python, Docker e GitLab ed è specializzato in programmazione orientata agli oggetti (OOP), controllo qualità e integrazione e consegna continua (CI/CD). Le conoscenze di Tim in vari linguaggi di programmazione come VBA e Go illustrano l'ampiezza delle sue capacità tecniche.
Chi dovrebbe sostenere questo test?
Analista Dati, Data Scientist, Sviluppatore Full-Stack, Sviluppatore Python, Sviluppatore di Software, Sviluppatore Web
Descrizione
Nel mondo data-centric di oggi, la capacità di gestire e manipolare efficacemente set di dati complessi è una competenza cruciale. Pandas è uno strumento veloce, potente, flessibile e facile da usare per l'analisi e la manipolazione dei dati open source, costruito sul linguaggio di programmazione Python. È uno standard de facto per l'elaborazione dei dati in Python ed è uno strumento che ogni data scientist deve conoscere.
Questo test valuta le conoscenze dei candidati e la loro competenza nell'utilizzo di questo strumento per gestire complesse attività di analisi dei dati. Copre una serie di argomenti tra cui importazione/esportazione dei dati, pulizia e trasformazione, filtraggio del frame dei dati, raggruppamento e ordinamento dei dati, gestione dei valori mancanti, analisi delle serie temporali e visualizzazione dei dati.
Ottenendo buoni risultati in questo test, i candidati dimostrano di poter gestire set di dati grandi e complessi, pulire e formattare dati non strutturati, estrarre preziose intuizioni che possono guidare il processo decisionale. Tali candidati sono preziosi in ruoli di data science, tra cui analisti di dati, ingegneri dei dati e data scientists.
Questo test valuta le conoscenze dei candidati e la loro competenza nell'utilizzo di questo strumento per gestire complesse attività di analisi dei dati. Copre una serie di argomenti tra cui importazione/esportazione dei dati, pulizia e trasformazione, filtraggio del frame dei dati, raggruppamento e ordinamento dei dati, gestione dei valori mancanti, analisi delle serie temporali e visualizzazione dei dati.
Ottenendo buoni risultati in questo test, i candidati dimostrano di poter gestire set di dati grandi e complessi, pulire e formattare dati non strutturati, estrarre preziose intuizioni che possono guidare il processo decisionale. Tali candidati sono preziosi in ruoli di data science, tra cui analisti di dati, ingegneri dei dati e data scientists.
Panoramica
Creatore della prova
Tim Funke
Ingegnere software presso Telekom
Con un'esperienza di otto anni presso Deutsche Telekom, Tim Funke ha dimostrato non solo la sua padronanza come ingegnere software, ma anche eccellenza come ingegnere DevOps e ingegnere dei dati. Gestisce tecnologie come Python, Docker e GitLab ed è specializzato in programmazione orientata agli oggetti (OOP), controllo qualità e integrazione e consegna continua (CI/CD). Le conoscenze di Tim in vari linguaggi di programmazione come VBA e Go illustrano l'ampiezza delle sue capacità tecniche.