Workflow
Test PySpark online - Valutazione delle competenze pre-assunzione
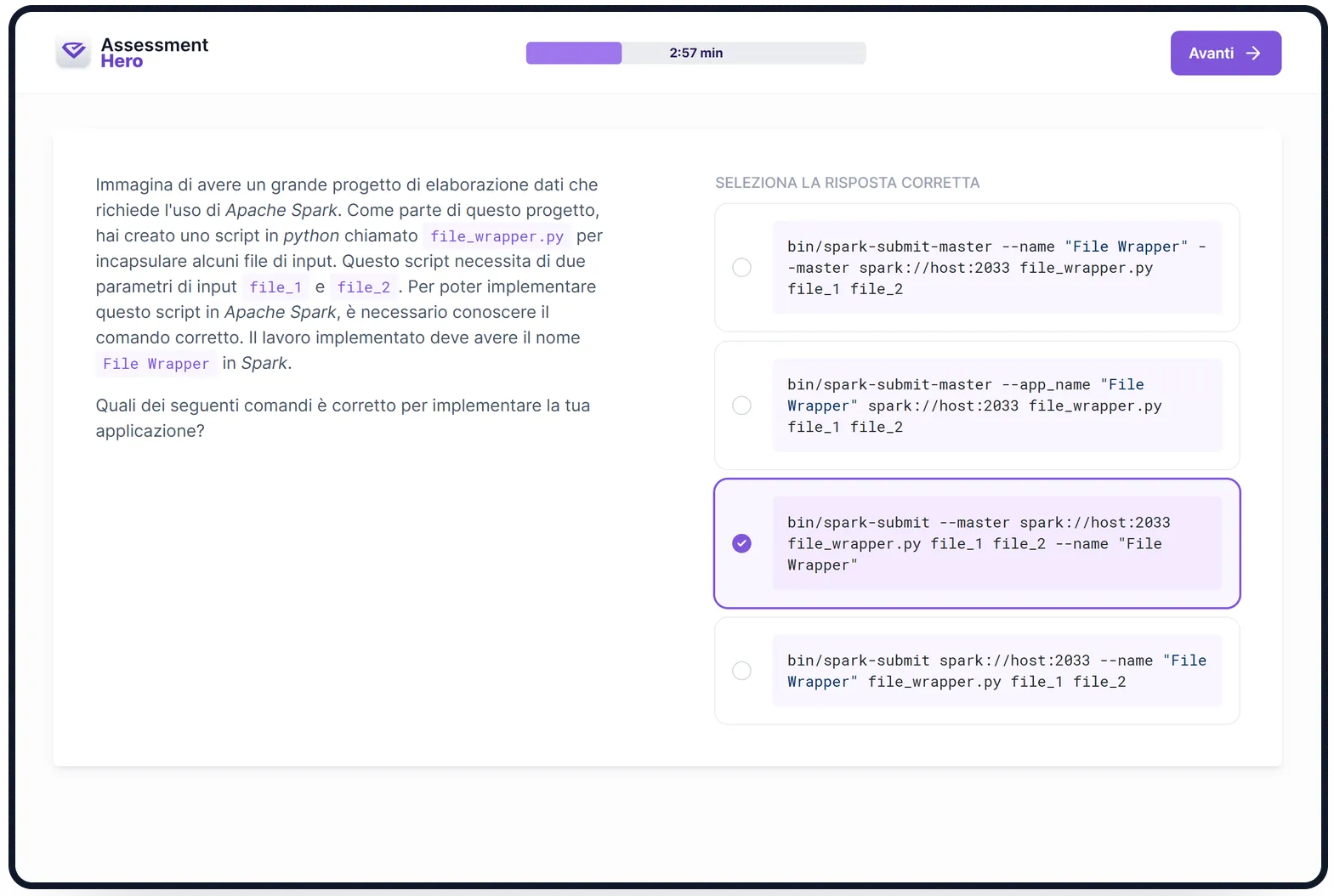
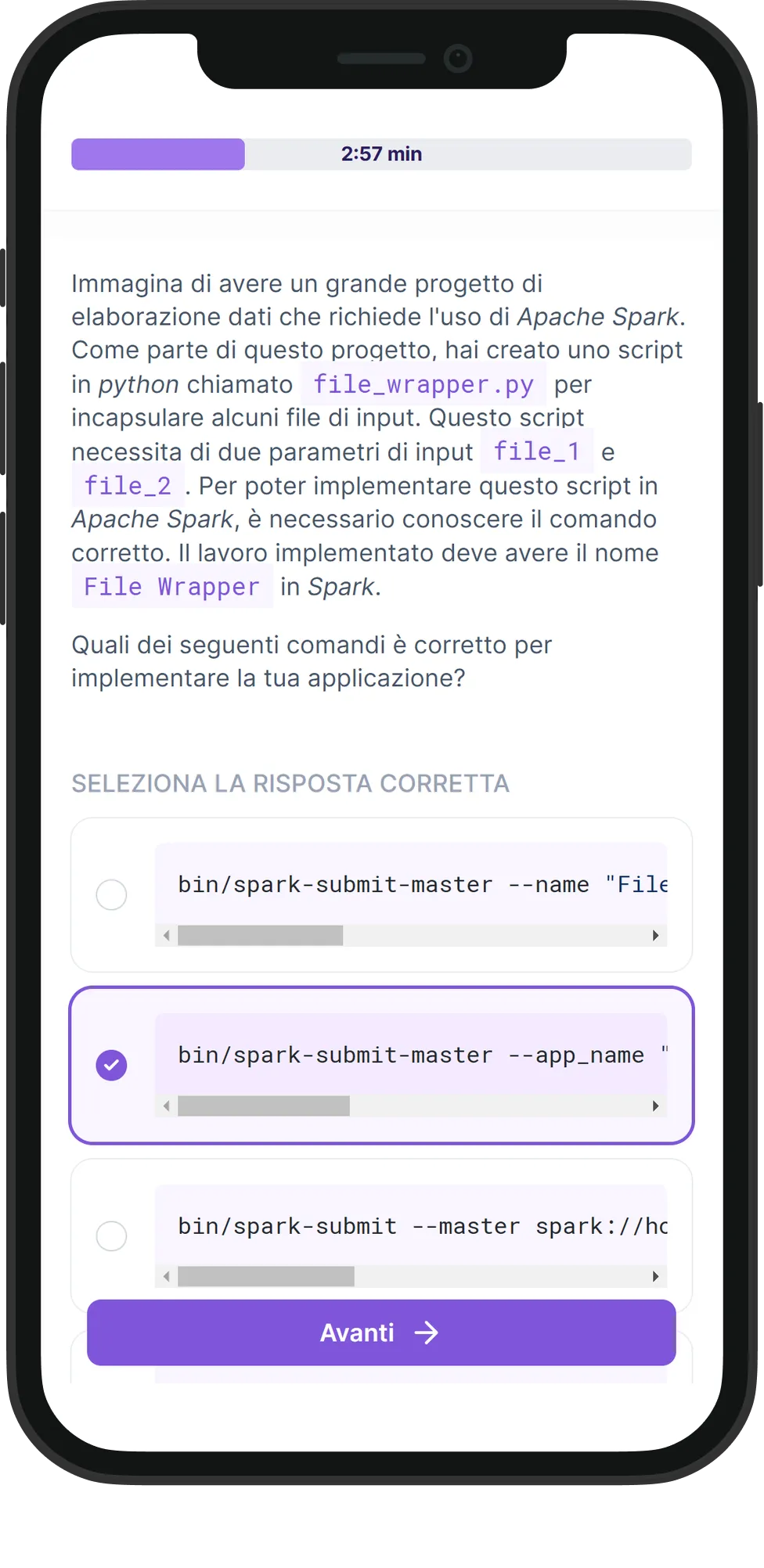
Di cosa tratta il test?
Questo test PySpark valuta la competenza dei candidati nelle applicazioni PySpark, concentrandosi sulla loro comprensione e utilizzo pratico dell'API PySpark e dell'elaborazione di big data.
Competenze coperte
Creatore della prova

Tim Funke
Ingegnere software presso Telekom
Con un'esperienza di otto anni presso Deutsche Telekom, Tim Funke ha dimostrato non solo la sua padronanza come ingegnere software, ma anche eccellenza come ingegnere DevOps e ingegnere dei dati. Gestisce tecnologie come Python, Docker e GitLab ed è specializzato in programmazione orientata agli oggetti (OOP), controllo qualità e integrazione e consegna continua (CI/CD). Le conoscenze di Tim in vari linguaggi di programmazione come VBA e Go illustrano l'ampiezza delle sue capacità tecniche.
Chi dovrebbe sostenere questo test?
Sviluppatore Back-End, Ingegnere Big Data, Sviluppatore Hadoop, Amministratore Spark, Sviluppatore Spark, Tester Spark
Descrizione
PySpark è una libreria Python per Apache Spark, un framework di calcolo cluster per l'analisi dei dati open-source. Fornisce un'interfaccia per la programmazione di Spark con Python, ed è particolarmente utile nelle attività di elaborazione di big data in cui la velocità di esecuzione di Python non è sufficiente.
Questo test PySpark è progettato per valutare le capacità dei candidati nell'uso di PySpark, ottimizzando la sua funzionalità per compiti di elaborazione e analisi dei dati. Il test valuta le loro abilità nelle operazioni RDD di PySpark, DataFrame, Spark SQL e nella libreria MLlib. Inoltre, verifica la loro comprensione delle tecniche di ottimizzazione nell'elaborazione dei big data come la partizione e la cache.
I candidati che eccellono in questo test dimostrano una forte comprensione delle funzionalità di PySpark e la capacità di sfruttarle per un'efficace elaborazione e analisi dei dati su larga scala. Queste competenze sono fondamentali per i data scientist, gli ingegneri dei dati e qualsiasi ruolo che si occupa di significative quantità di dati.
Questo test PySpark è progettato per valutare le capacità dei candidati nell'uso di PySpark, ottimizzando la sua funzionalità per compiti di elaborazione e analisi dei dati. Il test valuta le loro abilità nelle operazioni RDD di PySpark, DataFrame, Spark SQL e nella libreria MLlib. Inoltre, verifica la loro comprensione delle tecniche di ottimizzazione nell'elaborazione dei big data come la partizione e la cache.
I candidati che eccellono in questo test dimostrano una forte comprensione delle funzionalità di PySpark e la capacità di sfruttarle per un'efficace elaborazione e analisi dei dati su larga scala. Queste competenze sono fondamentali per i data scientist, gli ingegneri dei dati e qualsiasi ruolo che si occupa di significative quantità di dati.
Panoramica
Creatore della prova
Tim Funke
Ingegnere software presso Telekom
Con un'esperienza di otto anni presso Deutsche Telekom, Tim Funke ha dimostrato non solo la sua padronanza come ingegnere software, ma anche eccellenza come ingegnere DevOps e ingegnere dei dati. Gestisce tecnologie come Python, Docker e GitLab ed è specializzato in programmazione orientata agli oggetti (OOP), controllo qualità e integrazione e consegna continua (CI/CD). Le conoscenze di Tim in vari linguaggi di programmazione come VBA e Go illustrano l'ampiezza delle sue capacità tecniche.