Workflow
Test Pandas Python en ligne – Évaluation des compétences préalables à l'emploi
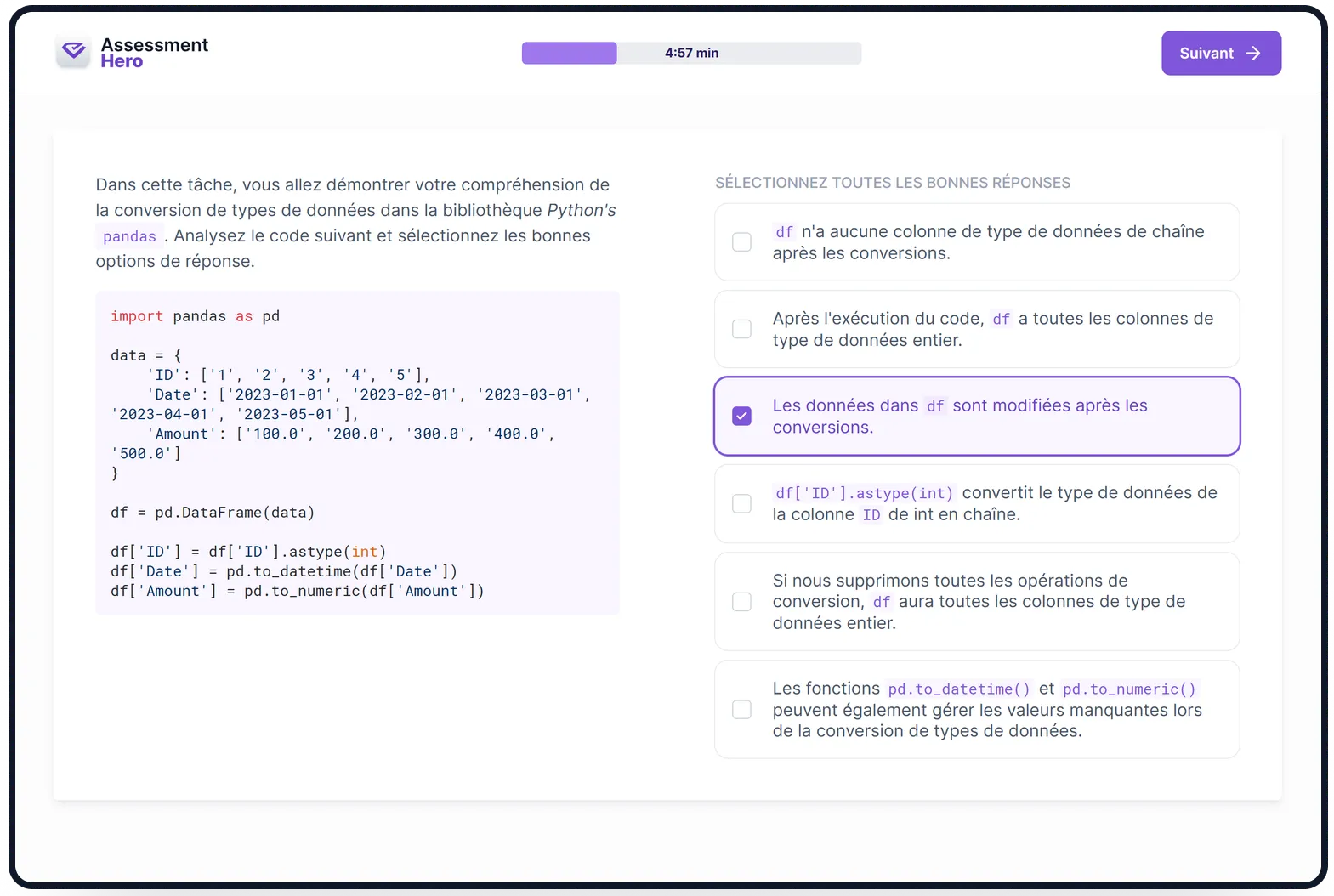
Sur quoi porte le test ?
Ce test évalue la compétence des candidats à utiliser Pandas, une bibliothèque Python puissante pour l'analyse et la manipulation des données. Il mesure leur capacité à nettoyer, transformer et visualiser des ensembles de données complexes en utilisant ce cadre.
Compétences couvertes
Créateur de tests

Tim Funke
Ingénieur logiciel chez Telekom
Avec huit ans d'expérience chez Deutsche Telekom, Tim Funke a non seulement démontré sa maîtrise en tant qu'ingénieur logiciel, mais a également excellé en tant qu'ingénieur DevOps et ingénieur en données. Il maîtrise des technologies telles que Python, Docker et GitLab et est spécialisé dans la programmation orientée objet (OOP), le contrôle qualité et l'intégration et la livraison continues (CI/CD). Les connaissances de Tim en divers langages de programmation comme VBA et Go illustrent la diversité de ses compétences techniques.
Qui devrait passer ce test ?
Analyste de Données, Data Scientist, Développeur Full-Stack, Développeur Python, Développeur de Logiciel, Développeur Web
Description
Dans le monde centré sur les données d'aujourd'hui, la capacité de gérer et de manipuler efficacement des ensembles de données complexes est une compétence cruciale. Pandas est un outil d'analyse et de manipulation de données open source, rapide, puissant, flexible et facile à utiliser, construit sur le langage de programmation Python. C'est une norme de facto pour le traitement des données en Python et un outil que chaque data scientist doit connaître.
Ce test évalue les connaissances et la compétence des candidats à utiliser cet outil pour gérer des tâches d'analyse de données sophistiquées. Il couvre une gamme de sujets, dont l'importation/exportation de données, le nettoyage et la transformation, le filtrage de l'ensemble de données, le groupement et le classement des données, la gestion des valeurs manquantes, l'analyse de séries temporelles et la visualisation de données.
En réussissant bien à ce test, les candidats démontrent qu'ils peuvent manipuler de grands ensembles de données complexes, nettoyer et formater des données non structurées, et extraire des informations précieuses qui peuvent orienter le processus de prise de décision. Ces candidats sont inestimables dans les rôles de science des données, y compris les analystes de données, les ingénieurs de données et les scientifiques de données.
Ce test évalue les connaissances et la compétence des candidats à utiliser cet outil pour gérer des tâches d'analyse de données sophistiquées. Il couvre une gamme de sujets, dont l'importation/exportation de données, le nettoyage et la transformation, le filtrage de l'ensemble de données, le groupement et le classement des données, la gestion des valeurs manquantes, l'analyse de séries temporelles et la visualisation de données.
En réussissant bien à ce test, les candidats démontrent qu'ils peuvent manipuler de grands ensembles de données complexes, nettoyer et formater des données non structurées, et extraire des informations précieuses qui peuvent orienter le processus de prise de décision. Ces candidats sont inestimables dans les rôles de science des données, y compris les analystes de données, les ingénieurs de données et les scientifiques de données.
Aperçu
Créateur de tests
Tim Funke
Ingénieur logiciel chez Telekom
Avec huit ans d'expérience chez Deutsche Telekom, Tim Funke a non seulement démontré sa maîtrise en tant qu'ingénieur logiciel, mais a également excellé en tant qu'ingénieur DevOps et ingénieur en données. Il maîtrise des technologies telles que Python, Docker et GitLab et est spécialisé dans la programmation orientée objet (OOP), le contrôle qualité et l'intégration et la livraison continues (CI/CD). Les connaissances de Tim en divers langages de programmation comme VBA et Go illustrent la diversité de ses compétences techniques.