Workflow
Online PySpark Test – Einstellungstest zur Bewerbervorauswahl
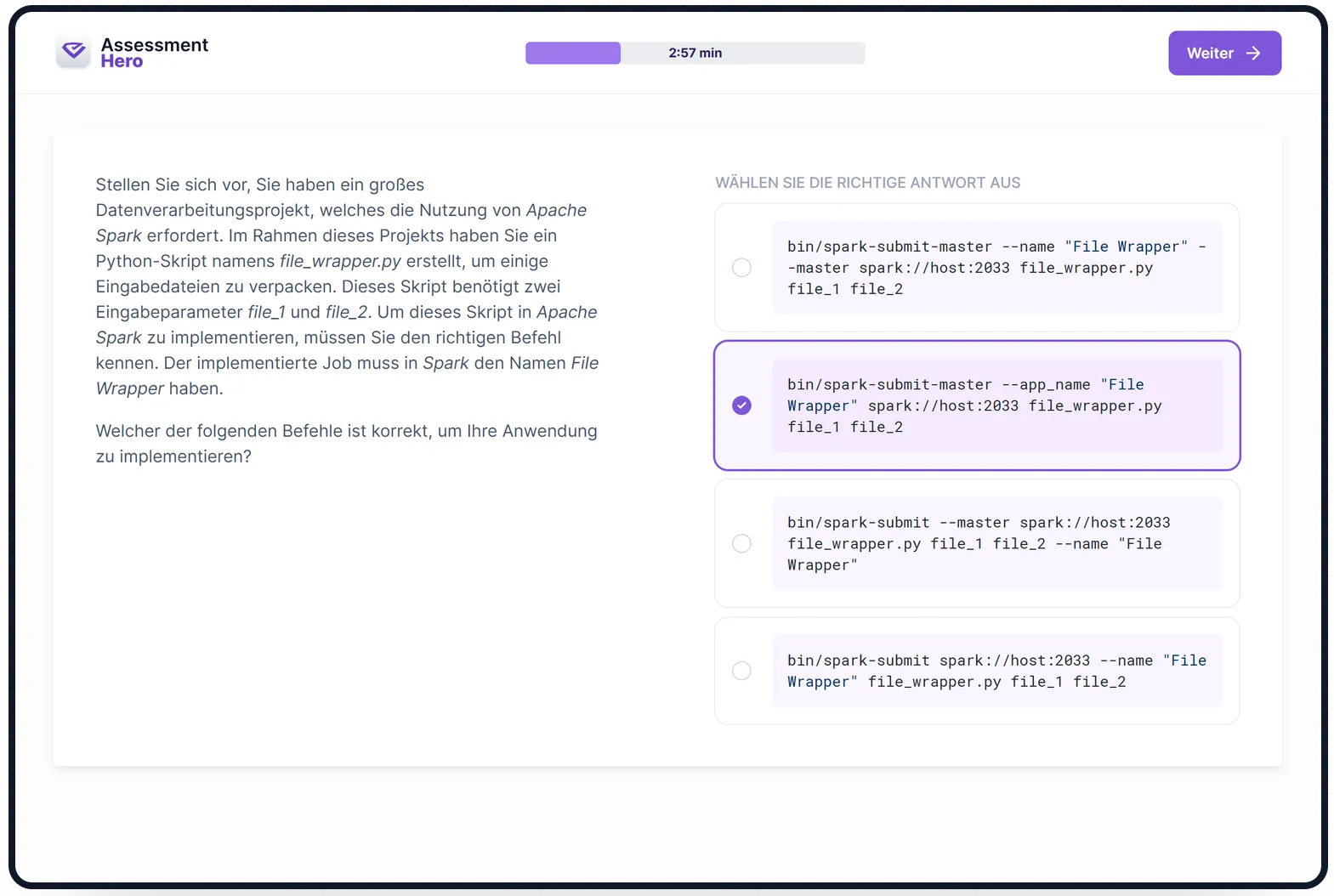
Worum geht es in dem Test?
Dieser PySpark-Test bewertet die Kompetenz von Kandidaten bei der Anwendung von PySpark und konzentriert sich dabei auf ihr Verständnis und die praktische Verwendung der PySpark API und der Big-Data-Verarbeitung.
Abgedeckte Fähigkeiten
Testersteller

Tim Funke
Softwareentwickler bei der Telekom
Mit einer achtjährigen Tätigkeit bei der Deutschen Telekom hat Tim Funke nicht nur seine Fähigkeiten als Softwareentwickler unter Beweis gestellt, sondern sich auch als DevOps- und Dateningenieur hervorgetan. Er beherrscht Technologien wie Python, Docker und GitLab und ist spezialisiert auf objektorientierte Programmierung (OOP), Qualitätssicherung und kontinuierliche Integration und Auslieferung (CI/CD). Tims Kenntnisse in verschiedenen Programmiersprachen wie VBA und Go verdeutlichen die Breite seiner technischen Fähigkeiten.
Wer sollte diesen Test machen?
Back-End-Entwickler, Big Data-Ingenieur, Hadoop-Entwickler, Spark-Administrator, Spark-Entwickler, Spark-Tester
Beschreibung
PySpark ist eine Python-Bibliothek für Apache Spark, einem Open-Source-Framework für Cluster-Computing und Datenanalytik. Es bietet eine Schnittstelle für die Programmierung von Spark mit Python und ist besonders nützlich bei Big-Data-Verarbeitungsaufgaben, bei denen die Leistungsgeschwindigkeit von Python nicht ausreicht.
Dieser PySpark-Test ist darauf ausgelegt, die Fähigkeiten der Kandidaten bei der Verwendung von PySpark zu bewerten und seine Funktionalität für Aufgaben der Datenverarbeitung und -analyse zu optimieren. Der Test bewertet ihre Fähigkeiten in den PySpark RDD-Operationen, DataFrames, Spark SQL und der MLlib-Bibliothek. Zusätzlich wird ihr Verständnis von Optimierungstechniken in der Big-Data-Verarbeitung, wie Partitionierung und Caching, überprüft.
Kandidaten, die in diesem Test hervorragende Leistungen erbringen, weisen ein starkes Verständnis der Funktionalitäten von PySpark und die Fähigkeit, sie für eine effiziente großskalige Datenverarbeitung und -analyse zu nutzen, nach. Diese Fähigkeiten sind von entscheidender Bedeutung für Datenwissenschaftler, Daten-Ingenieure und jede Rolle, die mit großen Datenmengen zu tun hat.
Dieser PySpark-Test ist darauf ausgelegt, die Fähigkeiten der Kandidaten bei der Verwendung von PySpark zu bewerten und seine Funktionalität für Aufgaben der Datenverarbeitung und -analyse zu optimieren. Der Test bewertet ihre Fähigkeiten in den PySpark RDD-Operationen, DataFrames, Spark SQL und der MLlib-Bibliothek. Zusätzlich wird ihr Verständnis von Optimierungstechniken in der Big-Data-Verarbeitung, wie Partitionierung und Caching, überprüft.
Kandidaten, die in diesem Test hervorragende Leistungen erbringen, weisen ein starkes Verständnis der Funktionalitäten von PySpark und die Fähigkeit, sie für eine effiziente großskalige Datenverarbeitung und -analyse zu nutzen, nach. Diese Fähigkeiten sind von entscheidender Bedeutung für Datenwissenschaftler, Daten-Ingenieure und jede Rolle, die mit großen Datenmengen zu tun hat.
Überblick
Testersteller
Tim Funke
Softwareentwickler bei der Telekom
Mit einer achtjährigen Tätigkeit bei der Deutschen Telekom hat Tim Funke nicht nur seine Fähigkeiten als Softwareentwickler unter Beweis gestellt, sondern sich auch als DevOps- und Dateningenieur hervorgetan. Er beherrscht Technologien wie Python, Docker und GitLab und ist spezialisiert auf objektorientierte Programmierung (OOP), Qualitätssicherung und kontinuierliche Integration und Auslieferung (CI/CD). Tims Kenntnisse in verschiedenen Programmiersprachen wie VBA und Go verdeutlichen die Breite seiner technischen Fähigkeiten.